拦截器
每一个Call请求都需要经过一些列的拦截器处理,Ok通过这些拦截器实现了对Call请求的重试、重定向、缓存
、设置请求头、压缩,甚至是最终对服务端的请求和接收返回数据也都是在拦截器中进行的;
RealCall.getResponseWithInterceptorChain1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
List<Interceptor> interceptors = new ArrayList<>();
// 添加我们通过addInterceptor添加的应用拦截器
interceptors.addAll(client.interceptors());
// 添加失败重试和请求重定向拦截器
interceptors.add(retryAndFollowUpInterceptor);
// 添加请求头信息、对接收内容进行gzip压缩
interceptors.add(new BridgeInterceptor(client.cookieJar()));
// 对请求进行缓存管理
interceptors.add(new CacheInterceptor(client.internalCache()));
// 从连接池中获取一个有效的连接(可能是重用的,也可能是新建的)
interceptors.add(new ConnectInterceptor(client));
// 如果不是通过WebSocket协议连接的,则还会添加网络拦截器,即我们通过addNetworkInterceptor
// 添加的拦截器
if (!forWebSocket) {
interceptors.addAll(client.networkInterceptors());
}
// 负责向服务器发起访问,并拿到最原始的返回数据往回传
interceptors.add(new CallServerInterceptor(forWebSocket));
// 创建拦截器链,用来处理每一个请求
Interceptor.Chain chain = new RealInterceptorChain(
interceptors, null, null, null, 0, originalRequest);
// 开始执行调用链
return chain.proceed(originalRequest);
}
请求的发起和接收,都是在拦截器中进行的,不管是异步还是同步请求,都会调用该方法,来启动拦截器链;
RealInterceptorChain
1 | public final class RealInterceptorChain implements Interceptor.Chain { |
RealInterceptorChain是Ok拦截器链,其中包含了Ok中所有的拦截器;
RealInterceptorChain贯穿了整个拦截链的始终,其中包含了Http请求需要的重要数据:request请求、
连接客户端(RealConnection)、以及连接和流(StreamAllocation)等;
每开启一个拦截器进行操作时,都会创建相应的RealInterceptorChain,用来将Http请求的数据封装,传
递给拦截器;
每一个拦截器的操作,都会通过RealInterceptorChain来获取其中需要的信息,并且最终会通过
RealInterceptorChain来推动,进入到下一个拦截器中进行拦截操作;
RetryAndFollowUpInterceptor
RetryAndFollowUpInterceptor是Call请求流程中第一个系统拦截器,其起到的主要作用是实现Call
请求的失败重试和重定向;
1、成员变量:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public final class RetryAndFollowUpInterceptor implements Interceptor {
/**
* How many redirects and auth challenges should we attempt? Chrome follows 21 redirects; Firefox,
* curl, and wget follow 20; Safari follows 16; and HTTP/1.0 recommends 5.
*/
// 最大的重定向和重试次数
private static final int MAX_FOLLOW_UPS = 20;
private final OkHttpClient client;
// 是否使用WebSocket协议
private final boolean forWebSocket;
// 用来从连接池找到合适的连接(新建,重用),创建数据流对象,用来进行数据通信
private StreamAllocation streamAllocation;
// 打印日志用的调用栈的跟踪对象
private Object callStackTrace;
// 标记当前请求是否已经取消了
private volatile boolean canceled;
2、cancel
我们可以通过Call的Cancel方法来取消当前正在执行的请求,则这个Cancel方法实际上就是调用
RetryAndFollowUpInterceptor的cancel方法;1
2
3
4
5
6
7
8public void cancel() {
// 标记当前的请求状态为取消
canceled = true;
// 通过StreamAllocation关闭连接和数据流
StreamAllocation streamAllocation = this.streamAllocation;
if (streamAllocation != null) streamAllocation.cancel();
}
3、createAddress
通过请求的链接信息(HttpUrl),构造出即将访问的服务器地址信息,包含了主机名,端口等,如果是通过
代理来请求的,还会包含代理的信息;如果是通过Https来请求的,则会为其创建SSL验证信息;
1 | private Address createAddress(HttpUrl url) { |
4、recover
当链接失败时,RetryAndFollowUpInterceptor拦截器会调用该方法尝试进行重连操作,如果请求带有
请求体,则只有在请求体已经被缓存的情况下,才能进行链接恢复。或者错误是在request请求被发送之前
出现的。
1 | // 参数2表示当前request请求是否已经发送了 |
5、isRecoverable
用来判断连接失败时,发出的异常是否是不可恢复的异常;
1 | private boolean isRecoverable(IOException e, boolean requestSendStarted) { |
如果异常是在我们连接到代理时发生的,并且是一个标准的IO异常,则判断是否是isRecoverable方法中指定要
拦截的异常,如果不是,则尝试一个新的路由;
6、followUpRequest
该方法用来检查服务端返回的response的状态,根据状态构造出新的包含安全认证的header,或者进行重定
向,或者处理为客户端连接超时(重新执行request请求)。如果接收该response之后不需要进行后续操作(
即直接返回),则返回null,否则返回更新后的request进行重新请求。
1 | private Request followUpRequest(Response userResponse) throws IOException { |
7、intercept
1 | @Override public Response intercept(Chain chain) throws IOException { |
RetryAndFollowUpInterceptor虽然是整个系统拦截链的第一个拦截器,但是其作用时期却是在整个Http
请求的最后环节;
RetryAndFollowUpInterceptor的一个作用就是捕获整个拦截器链处理过程的异常,判断该异常下是否
要重走整个请求流程(注意,不是请求重试和重定向,因为此时followUpCount是重新置为0的,相当于之前
的请求都抛弃了,重新再来)。
RetryAndFollowUpInterceptor的另一个作用是在服务端返回response,经过了多个拦截器处理之后,
在最终到达RetryAndFollowUpInterceptor这里时,解析response中的响应码,如果需要进行重新请求
(可能是要进行重定向,也可能是其他情况,比如客户端超时,导致要进行重新请求),则会重新创建一个
request请求,进行请求,直到请求结束,则将response返回给客户端进行处理;
https://blog.csdn.net/sdfdzx/article/details/78186164
https://www.jianshu.com/p/e3b6f821acb8
https://yq.aliyun.com/articles/78104?spm=a2c4e.11153940.blogcont78101.13.30493cbfGzKQVY
https://www.jianshu.com/p/9deec36f2759
https://www.jianshu.com/p/6166d28983a2
https://www.jianshu.com/p/671a123ec163
https://www.jianshu.com/p/92ce01caa8f0
BridgeInterceptor
顾名思义,BridgeInterceptor起到桥接的作用。BridgeInterceptor将应用程序的用户请求数据转化为
对应网络请求数据;在网络请求之后,又将对应的服务端返回数据,转化为对应的用户相应数据;
BridgeInterceptor为request设置各种请求报头,从response中读取并保存cookie,并解压服务端返回
的gzip格式的数据作为response的相应体数据;
1 | public final class BridgeInterceptor implements Interceptor { |
BridgeInterceptor的一个职责是构造出一个新的request副本,并解析旧request中的信息,作为请求头
添加进新的request中(这就是将应用程序的用户请求数据转化为对应网络请求数据的过程);
BridgeInterceptor对cookie进行了管理,但ok默认是不接收服务端设置的cookie的,需要我们自己实现
cookieJar,完成存取逻辑;
BridgeInterceptor会对服务端返回的gzip格式的响应体进行解压,并重新赋给响应体,这样免去了应用层
解压的麻烦;
BridgeInterceptor的另一个职责是构造出一个新的response副本,解析旧response的cookie信息进行
保存,解压响应体,赋给新response的响应体(这就是将服务端响应数据转化为用户数据的过程);
https://www.jianshu.com/p/e3b6f821acb8
https://yq.aliyun.com/articles/78104?spm=a2c4e.11153940.blogcont78105.12.563837beQ4QiO4
CacheInterceptor
CacheInterceptor用来决策当前网络请求是否使用缓存,并且会根据缓存策略决定是否进行缓存和删除缓
存。
CacheStrategy
CacheStrategy接收当前request请求和可能存在的response缓存,并根据这两者设置的头数据来决策是
使用缓存,还是进行网络请求,还是两者都进行;
1、CacheStrategy
根据response的状态码判断当前的response是否能被缓存;
1 | public static boolean isCacheable(Response response, Request request) { |
2、Factory
根据request、response和系统当前事件构造相应的CacheStrategy实例;
1 | public static class Factory { |
3、构造方法
接收当前系统时间、request请求和缓存的response,解析缓存和有效期有关的响应头数据;
1 | public Factory(long nowMillis, Request request, Response cacheResponse) { |
4、getCandidate
解析缓存响应头中的关于缓存使用期限的标识,构造出新的request、response或者为空的response;
1 | private CacheStrategy getCandidate() { |
5、get
调用getCandidate方法,获取CacheStrategy实例,但并不一定使用,还要进行多一层判断;
1 | public CacheStrategy get() { |
CacheInterceptor
成员变量:
1 | final InternalCache cache; |
CacheInterceptor 只有一个成员变量cache,提供了缓存、读取、删除、更新response的功能,并且以
请求的url为key;
ok提供了默认的cache(基于DiskLruCache),使用时我们只需要创建对应Cache实例即可。当然,我们
还可以实习自己的缓存类,只需要实现InternalCache接口即可。
intercept
1 | @Override public Response intercept(Chain chain) throws IOException { |
CacheInterceptor的主要职责是管理response缓存,正常情况下,除非在response和request中显式
指定了no-store,否则只要提供了Cache,则ok会为我们缓存存在响应体的response数据;
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Age
https://www.jianshu.com/p/b32d13655be7
https://yq.aliyun.com/articles/78104?spm=a2c4e.11153940.blogcont78105.12.563837beQ4QiO4
https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Age
https://blog.csdn.net/cominglately/article/details/77685214
ConnectInterceptor
ConnectInterceptor职责很简单,就是管理当前Call请求与服务端的连接;
RealConnection
RealConnection负责与服务端建立连接(通过三次握手、四次挥手);
RealConnection创建、包装和操作Socket,每一个RealConnection对应一个连接的Socket;
RealConnection代表连接Socket的链路,如果创建了RealConnection实例,则表明我们已经跟服务端建立
了一条通信链路;
RealConnection采用的连接协议有HTTP1.x、HTTPS和HTTP2三种网络协议进行连接;
当RealConnection是基于HTTP2协议是,则可以承载多个数据流(对应多个StreamAllocation);
建立HTTPS和HTTP2的流程是先创建一个普通的rawSocket,可以用来完成HTTP1.x请求,如果当前连接支持
HTTPS或HTTP2,则会在构造SSLSocket,用来完成带安全验证的HTTP请求;
属性:
1 | private final ConnectionPool connectionPool; |
connectSocket
创建一个最基本的Socket,支持HTTP连接,并且可以扩展为HTTPS连接
1 | /** Does all the work necessary to build a full HTTP or HTTPS connection on a raw socket. */ |
createTunnel
创建一个连接管道;
1 | private Request createTunnel(int readTimeout, int writeTimeout, Request tunnelRequest, |
connectTunnel
以管道方式建立连接(就是建立一个TCP长连接,将所有的请求都交给这个连接处理,这些请求被按顺序发送和
接收,当一个请求耗时过长时,后续请求将会受到阻塞);
1 | private void connectTunnel(int connectTimeout, int readTimeout, int writeTimeout) |
establishProtocol
如果是基于HTTPS或者HTTP2协议的连接,则必须经过下面的方法。
1 | private void establishProtocol(ConnectionSpecSelector connectionSpecSelector) throws IOException { |
connect
1 | public void connect( |
StreamAllocation
StreamAllocation的作用是协调连接(Connections)、数据流(Streams)和请求(Calls)之间的关系;
连接指的是Socket与远程服务端的连接。创建连接的过程可能很缓慢,所以我们可以直接取消掉一个
正在创建的连接。
数据流表示建立在连接之上的逻辑请求和响应数据。每一个连接能够携带的数据流个数都是有限制的,HTTP1.x
协议,每一个连接都只能够携带一个数据流,而HTTP2采用了连接复用技术,所以同一连接可以携带多个数据流。
请求,即Call请求,通过request发起。一个请求对应了一些列的数据流,典型的是一个初始化请求和其后的
一系列重定向请求,每一个请求对应一个数据流。我们更希望一个请求的所有数据流都使用一个相同的连接,
这样比在不同的连接上将有更好的行为和位置优势(同一个位置更便于管理和操作)。
HTTP2相对于HTTP1.x解决了连接无法复用的问题。所谓的连接复用,就是多个stream流都采用同一Socket
进行连接,这些Stream都有一个相同的特征,就是它们的host和port必须是相同的,每一个stream代表一次
request请求。通过复用同一个Socket连接,能够显著的减少Socket建立TCP连接时,三次握手的时间。
StreamAllocation的实例代表这一个使用一个或多个基于一个或多个连接的数据流(说白了就是一个请求的
数据流管理类),这个类提供了基于这些连接资源的释放API:
noNewStreams
noNewStreams方法能够防止一个连接被再次创建一个新的数据流,这个方法一般用在连接的close方法被调
用,或者连接与需求不符的情况下。
streamFinished
streamFinished用来释放当前allocation中保存的活跃的数据流。
在同一时刻,只有一个连接可能是处于活跃状态,所以在创建其他的数据流之前,必须确保已经调用了本方
法将活跃的连接关闭掉。
release
release方法的作用是移除当前连接上的请求(多个Stream);
如果当前连接上任然存在一个活跃的数据流,则调用这个方法不会立马释放连接。比如,当一个请求已经
结束了,但是,我们还没有使用完response的响应体数据(通过response读取网络文件输出流)。
上面三种管理连接的方式,在StreamAllocation中对应了三个方法,这三个方法都调用了:1
2
3private Socket deallocate(boolean noNewStreams, boolean released, boolean streamFinished) {
...
}
来进行连接的管理。无论是通过哪种方式,都无法单独做到将连接置为空闲的效果。只有在streamFinished
为true,即数据流是关闭或者为创建的状态,才能将当前的连接置为空闲状态(Socket也会同时关闭)。
cancel
cancel 方法用来取消掉当前的数据流和连接,支持异步的调用。如果数据流是基于HTTP2协议的,则在
调用该方法时,只会关闭该数据流,连接和共享该连接的其他数据流不会受到影响。
如果连接正处于TLS握手阶段(即还没正式建立起来),调用该方法可能会打断整个连接。
findConnection
该方法将返回一个持有新的数据流的连接,如果已经存在现成可用的连接,则会直接使用;否则会先创建
连接,放入连接池;
1 | private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout, |
releaseAndAcquire
释放当前Allocation持有的连接,并用传递进来的连接进行代替。在同时有多个HTTP2异步请求发出时,
如果发现Allocation新建的连接已经存在了,可以调用该方法,实现线程安全的去重操作;
1 | public Socket releaseAndAcquire(RealConnection newConnection) { |
deallocate
deallocate方法用来把当前StreamAllocation持有的连接释放掉。
1 | private Socket deallocate(boolean noNewStreams, boolean released, boolean streamFinished) { |
findHealthyConnection
获取一个可以使用的连接;
1 | private RealConnection findHealthyConnection(int connectTimeout, int readTimeout, |
noNewStreams
这个方法的主要作用是设置当前的StreamAllocation的连接不能再创建新的数据流;
1 | public void noNewStreams() { |
newStream
创建一个新的数据流;
1 | public HttpCodec newStream(OkHttpClient client, boolean doExtensiveHealthChecks) { |
ConnectInterceptor.intercept
至此,ConnectInterceptor的intercept方法的流程也就很明确了!
1 | public final class ConnectInterceptor implements Interceptor { |
拿到在RetryAndFollowUpInterceptor中创建的StreamAllocation实例(在这里才算是第一使用了
StreamAllocation),通过StreamAllocation创建新的数据流,获取可用的连接(连接也可能是在创建
新数据流的过程中创建的,也可能是从连接池中拿的),传递给RealInterceptorChain的proceed方法,
推动拦截链进入系统拦截器的最后一个环节——CallServerInterceptor。
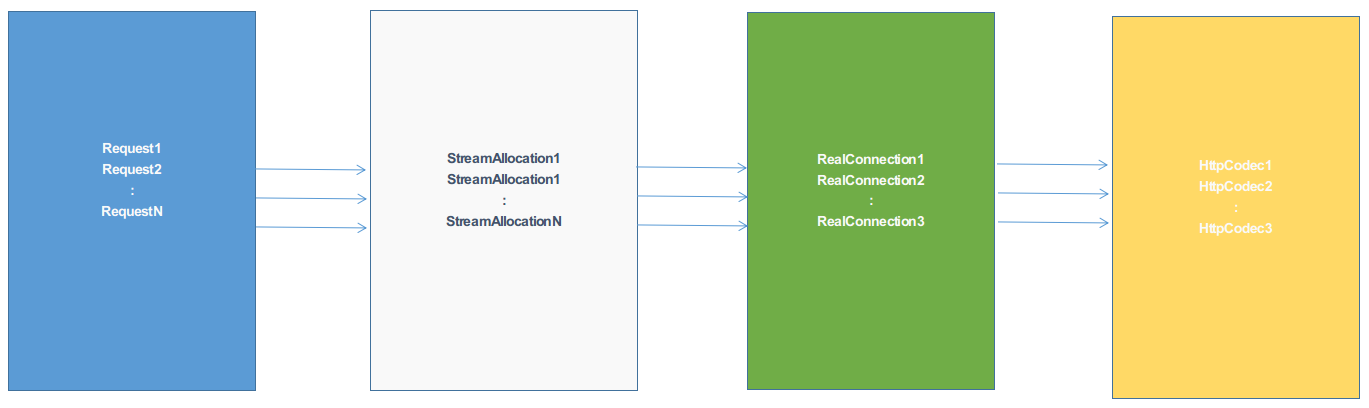
每一个请求都对应这一个StreamAllocation、一个RealConnection、一个HttpCodec;
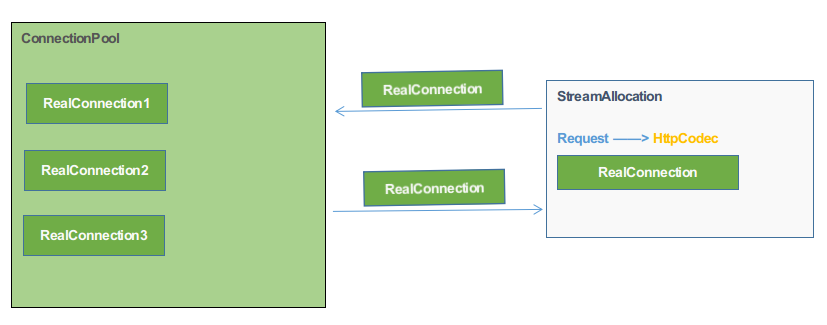
在StreamAllocation中,在创建新的数据流时,会从连接池中查找是否有可复用的连接,没有才会创建
新的连接,并把新的连接放入到连接池中,在放入连接池的同时,连接池会把当前空闲最久的连接的给移除掉;
在StreamAllocation中,根据Address和Route信息,可能从缓存池中获取出一个连接RealConnection,
也可能是新建一个RealConnection(创建后会把RealConnection放入到ConnectionPool中),最终的目的
是将Request转化为一个对应数据流(HttpCodec),用来与服务端进行数据通信.

对于基于HTTP1.x协议的连接,一个连接只能同时被一个请求使用,也就是说一个RealConnection中
同时只会存在一个SteamAllocation,而一个SteamAllocation对应一个数据流,当同时有多个请求对
同一个地址路由发起请求时,需要建立多个连接,所以Http1.x效率是低下的。(这并不以为着每次请求都
需要进行三次握手,因为有连接池的存在,对于同一个地址路由的请求,能够复用连接,但这种方式,拿到
缓存的连接可能会失效!)
HTTP1.x协议中有一种建立管道通信方式的长连接,这种方式虽然也能够省去建立连接时的握手时间,并且
不像缓存一样,连接会失效,但这种方式会一直占用着连接,对于通信不频繁的情况,将会浪费资源。
HTTP2协议的连接,支持连接复用,也就是说,一个连接可以被多个请求同时使用,对应的就是一个
RealConnection可以对应(保存)多个StreamAllocation。一个连接中将会同时有多个StreamAllocation
在进行数据通信(实际上,虽然实现了连接复用,但多个数据流并不是在通道中并发传输的,而是需要排队
顺序通过连接通道,到达服务端后,根据序号再各自组成完整数据请求);
CallServerInterceptor
到此拦截器,我们已经与服务端建立了连接,接下来在CallServerInterceptor中进行了Stream数据流的
沟通;
intercept
1 | @Override public Response intercept(Chain chain) throws IOException { |
HttpCodec可以认为是http请求中的解码器,在与服务的那成功建立连接后,利用其向服务端写入请求和读
取响应数据,其根据HTTP协议的不同,分别采用HttpCodec1(HTTP1.x)和HttpCodec2(HTTP2)来进行处理;